Shantanu Ghosh1,
Rayan Syed1,
Chenyu Wang1,
Vaibhav Choudhary1,
Binxu Li2,
Clare B. Poynton3,
Shyam Visweswaran4,
Kayhan Batmanghelich1
1Boston University, 2Stanford University, 3BUMC, 4Pitt DBMI
Accepted at ACL 2025 Findings
TL;DR: LADDER is a modular framework that uses large language models (LLMs) to discover, explain, and mitigate hidden biases in vision classifiers—without requiring prior knowledge of bias attributes.
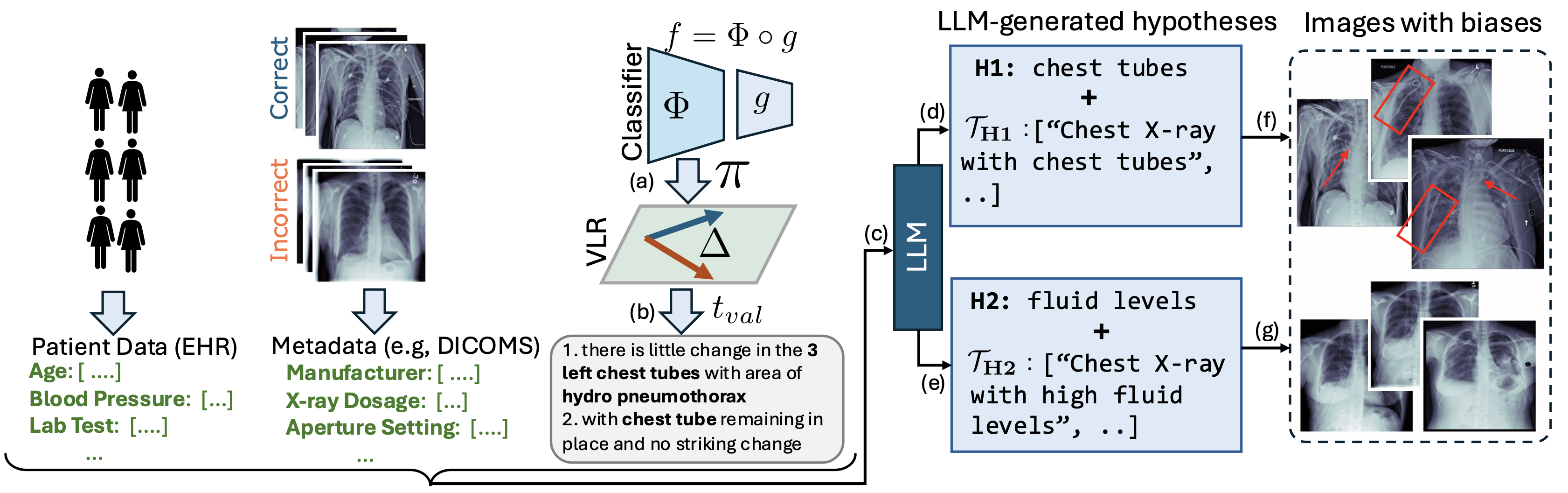
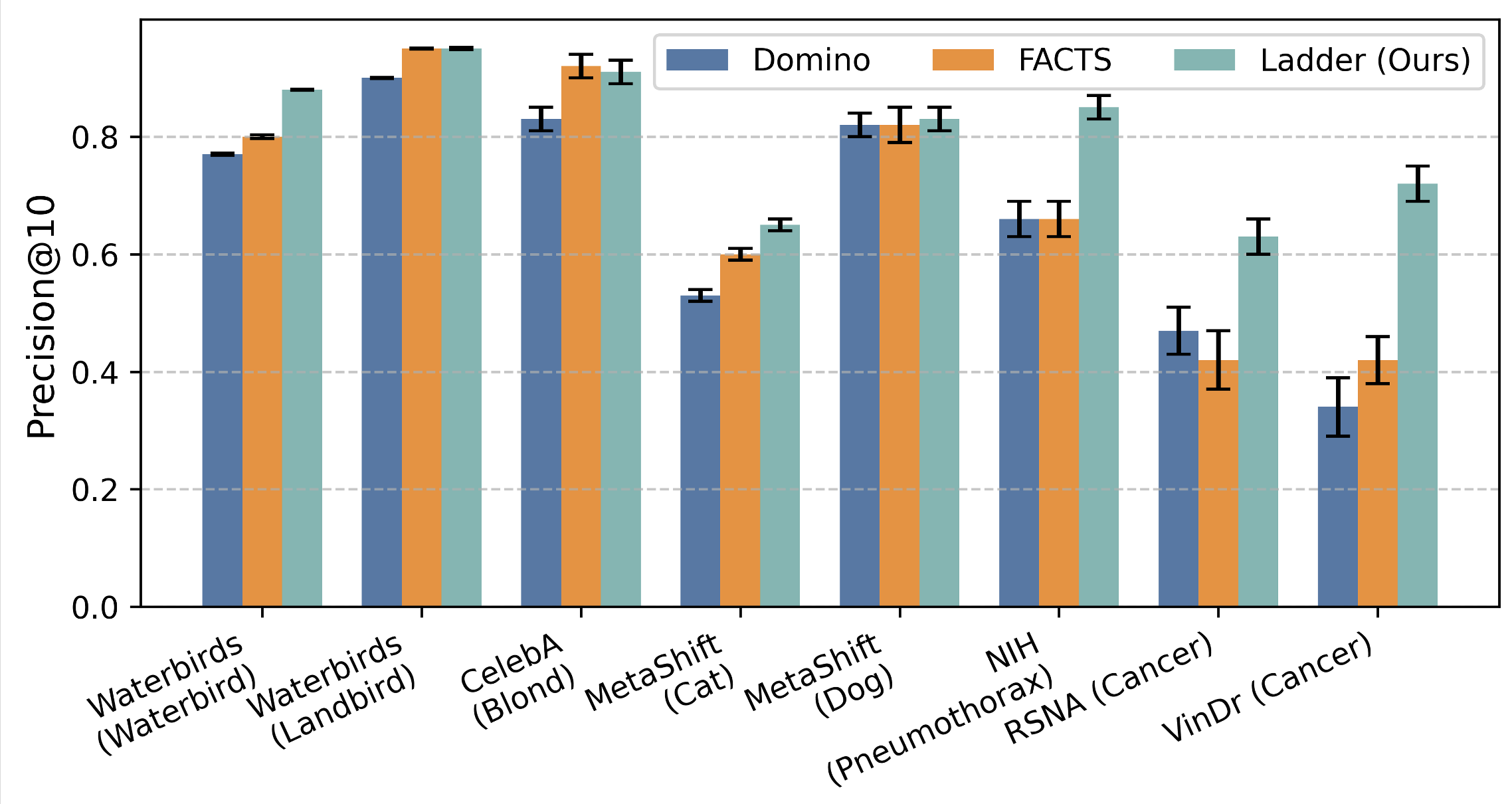
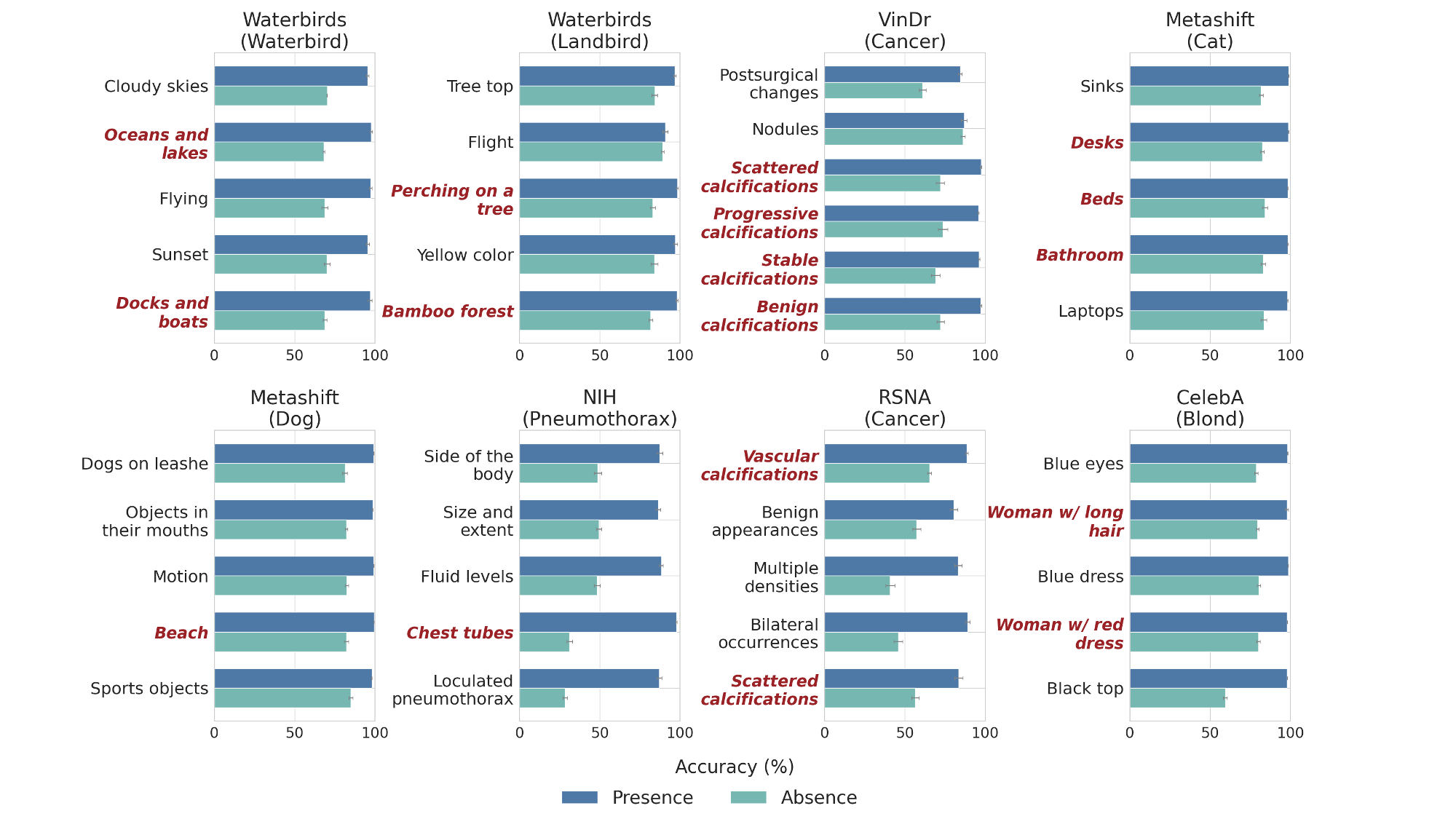
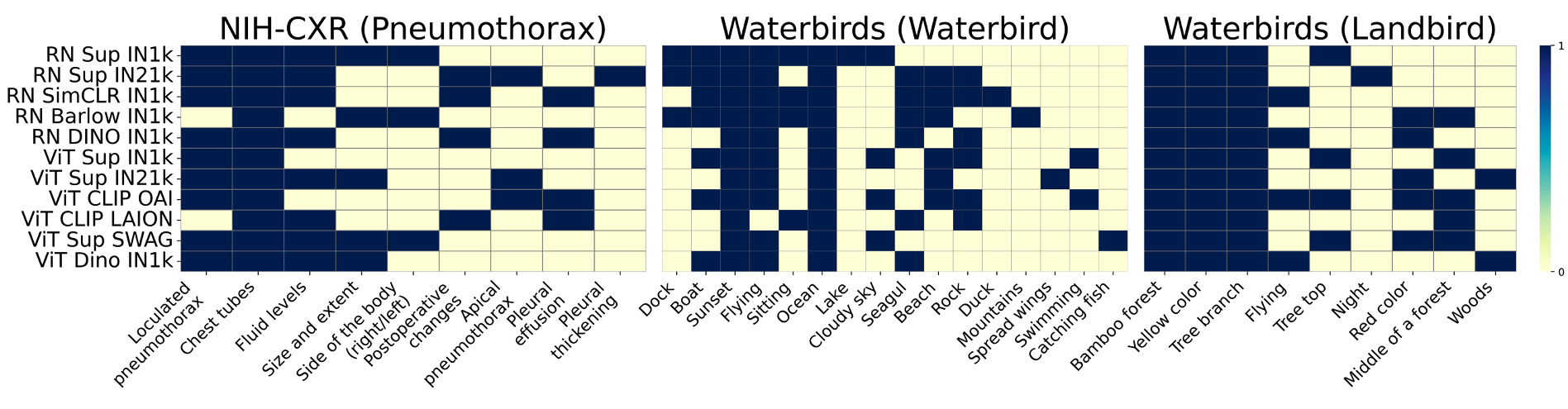
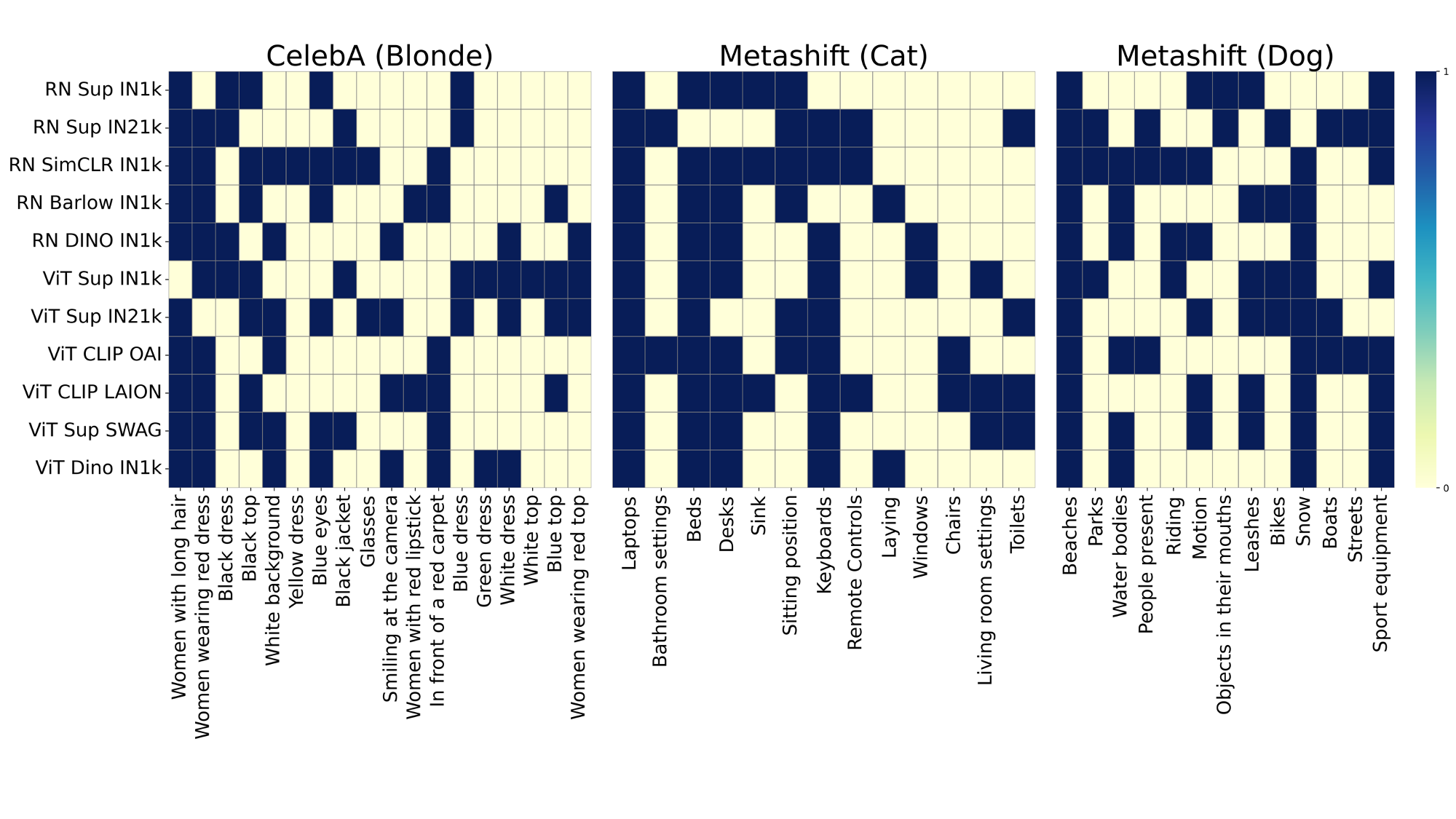
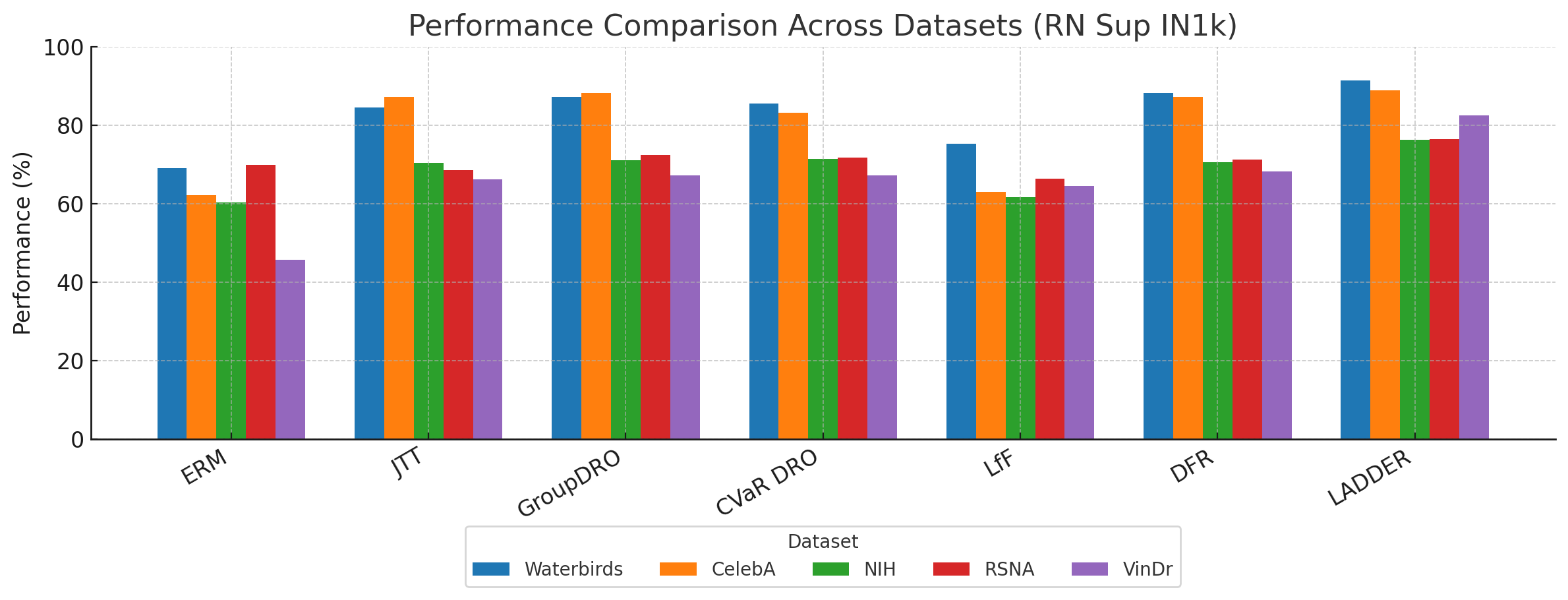
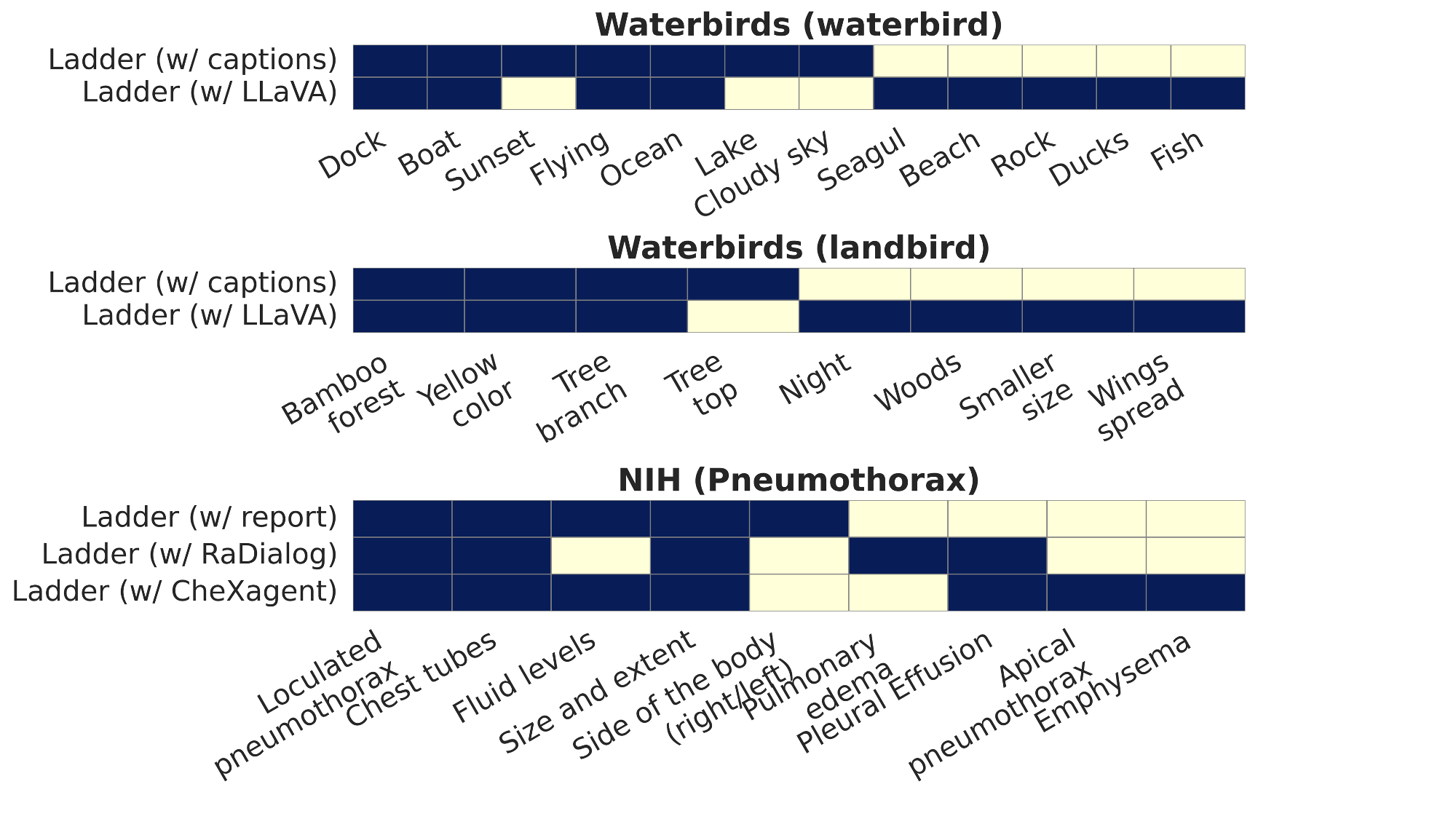
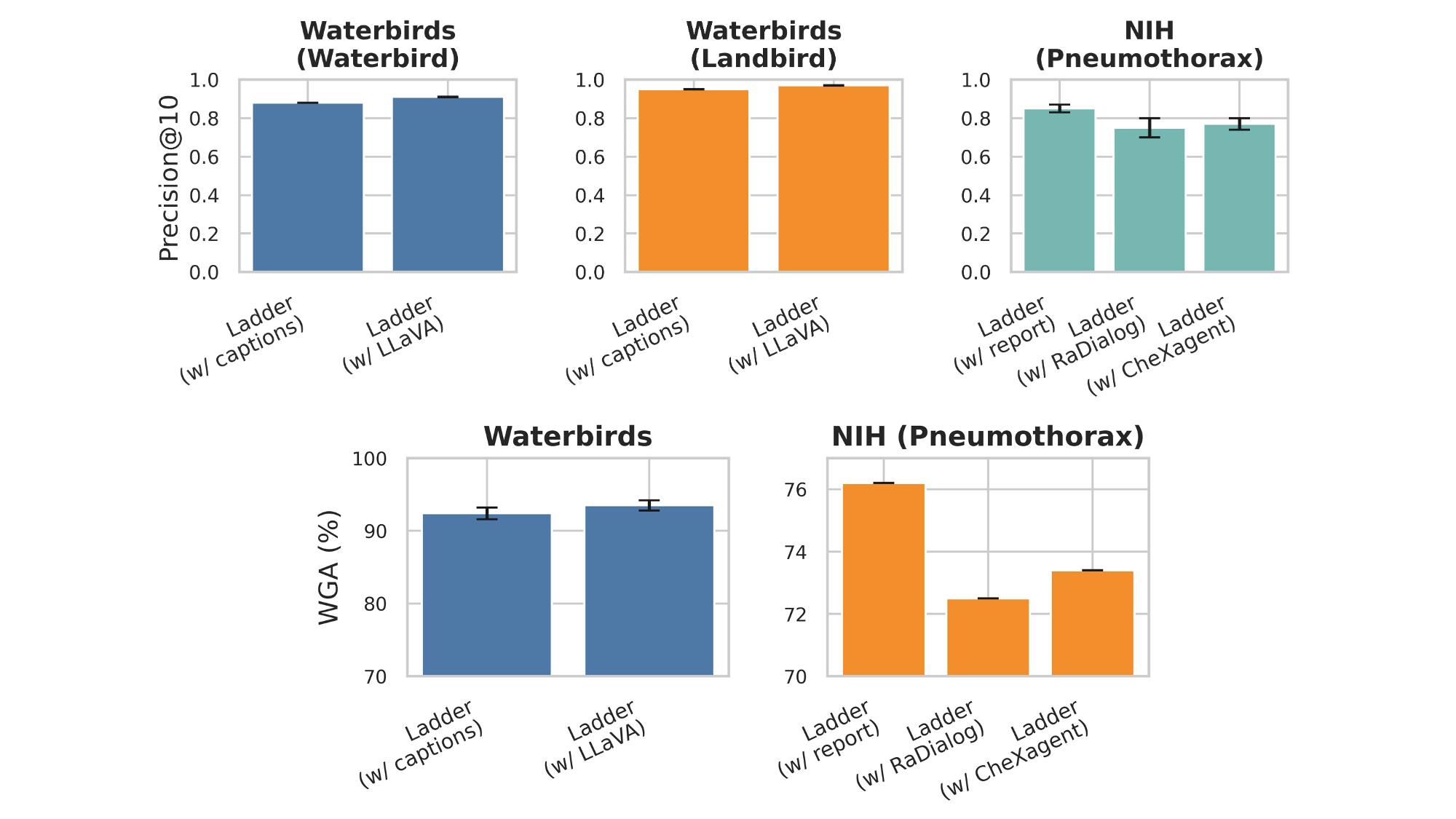
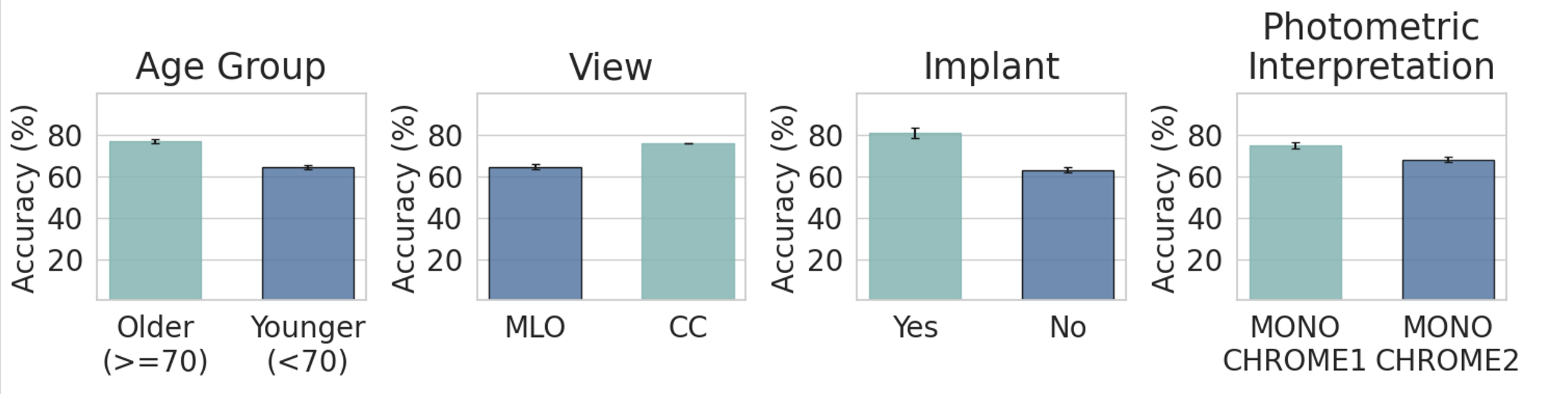
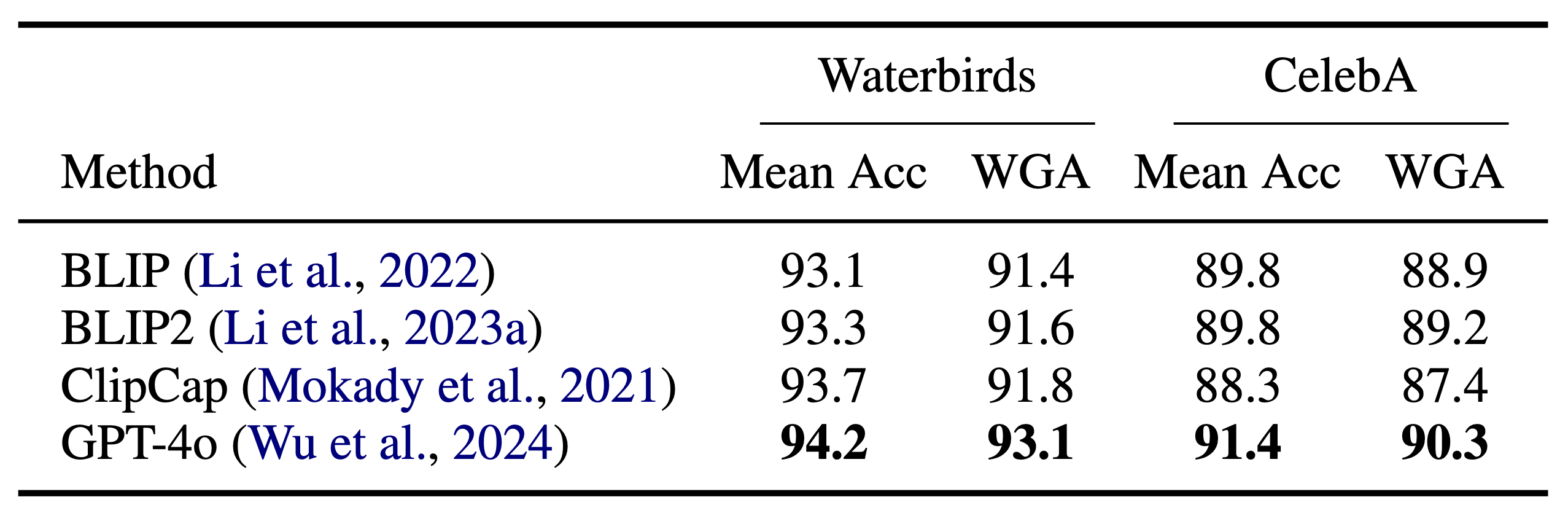
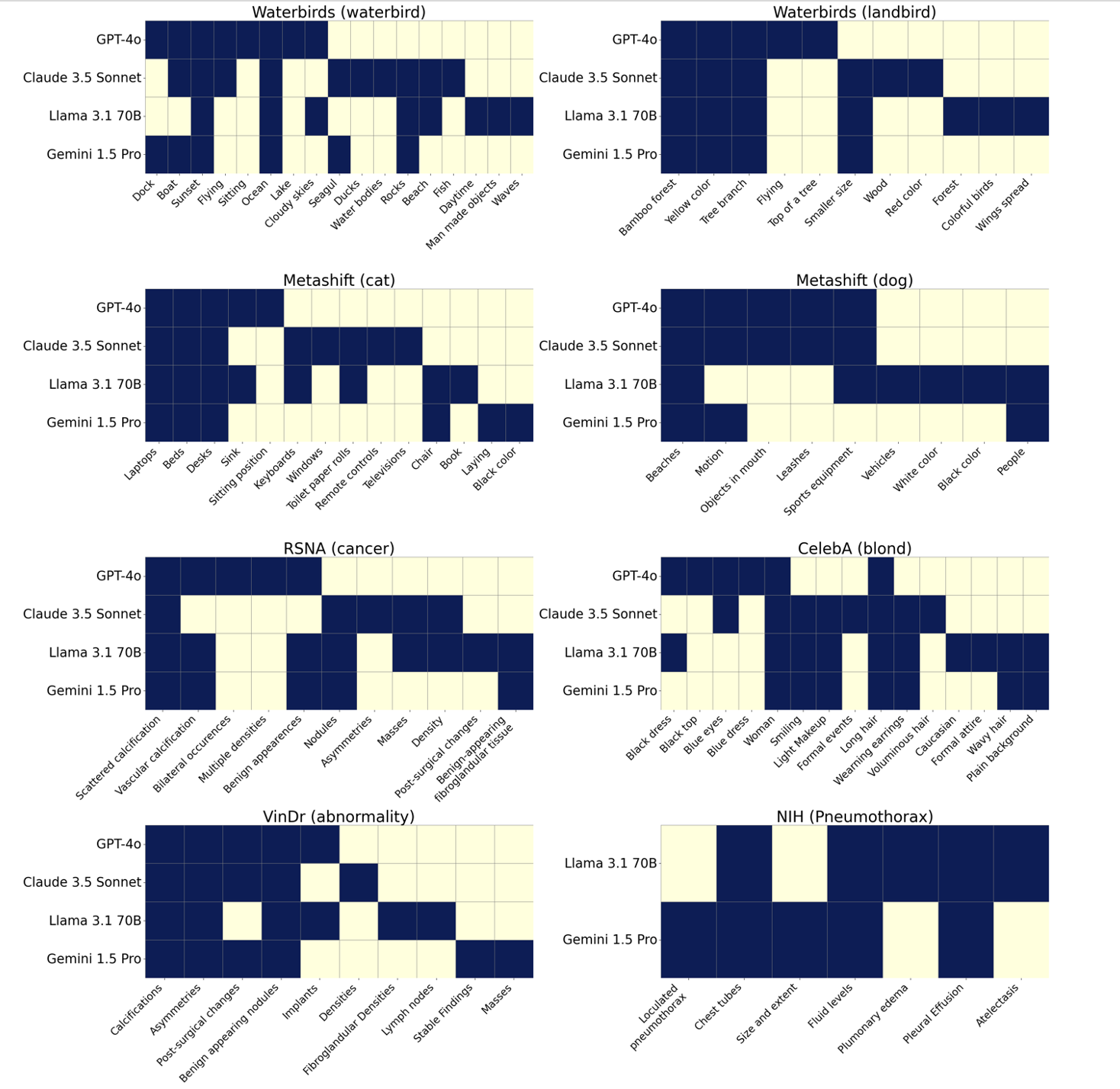
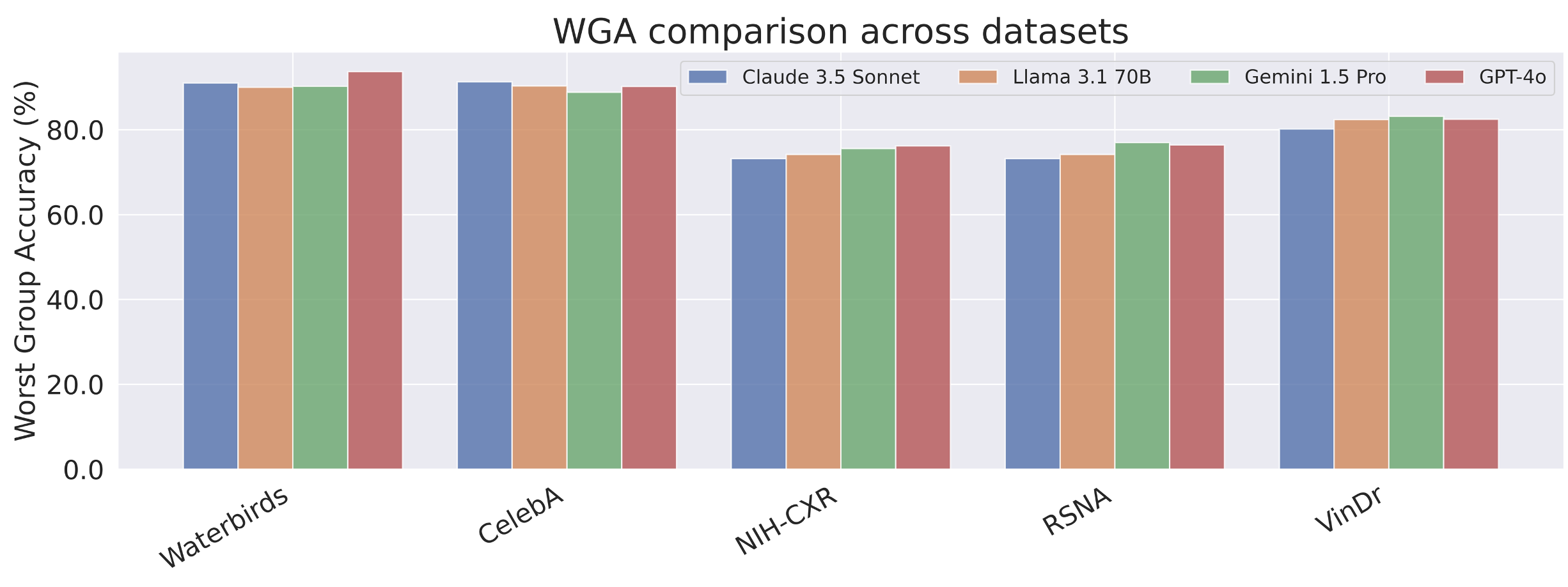
Slice discovery refers to identifying systematic biases in the mistakes of pre-trained vision models. Current slice discovery methods in computer vision rely on converting input images into sets of attributes and then testing hypotheses about configurations of these pre-computed attributes associated with elevated error patterns. However, such methods face several limitations: 1) they are restricted by the predefined attribute bank; 2) they lack the common sense reasoning and domain-specific knowledge often required for specialized fields e.g, radiology; 3) at best, they can only identify biases in image attributes while overlooking those introduced during preprocessing or data preparation. We hypothesize that bias-inducing variables leave traces in the form of language (e.g, logs), which can be captured as unstructured text. Thus, we introduce LADDER, which leverages the reasoning capabilities and latent domain knowledge of Large Language Models (LLMs) to generate hypotheses about these mistakes. Specifically, we project the internal activations of a pre-trained model into text using a retrieval approach and prompt the LLM to propose potential bias hypotheses. To detect biases from preprocessing pipelines, we convert the preprocessing data into text and prompt the LLM. Finally, LADDER generates pseudo-labels for each identified bias, thereby mitigating all biases without requiring expensive attribute annotations. Rigorous evaluations on 3 natural and 3 medical imaging datasets, 200+ classifiers, and 4 LLMs with varied architectures and pretraining strategies -- demonstrate that LADDER consistently outperforms current methods.
@inproceedings{ghosh-etal-2025-ladder,
title = "{LADDER}: Language-Driven Slice Discovery and Error Rectification in Vision Classifiers",
author = "Ghosh, Shantanu and
Syed, Rayan and
Wang, Chenyu and
Choudhary, Vaibhav and
Li, Binxu and
Poynton, Clare B and
Visweswaran, Shyam and
Batmanghelich, Kayhan",
editor = "Che, Wanxiang and
Nabende, Joyce and
Shutova, Ekaterina and
Pilehvar, Mohammad Taher",
booktitle = "Findings of the Association for Computational Linguistics: ACL 2025",
month = jul,
year = "2025",
address = "Vienna, Austria",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.findings-acl.1177/",
pages = "22935--22970",
ISBN = "979-8-89176-256-5",
abstract = "Slice discovery refers to identifying systematic biases in the mistakes of pre-trained vision models. Current slice discovery methods in computer vision rely on converting input images into sets of attributes and then testing hypotheses about configurations of these pre-computed attributes associated with elevated error patterns. However, such methods face several limitations: 1) they are restricted by the predefined attribute bank; 2) they lack the \textit{common sense} reasoning and domain-specific knowledge often required for specialized fields radiology; 3) at best, they can only identify biases in image attributes while overlooking those introduced during preprocessing or data preparation. We hypothesize that bias-inducing variables leave traces in the form of language (logs), which can be captured as unstructured text. Thus, we introduce ladder, which leverages the reasoning capabilities and latent domain knowledge of Large Language Models (LLMs) to generate hypotheses about these mistakes. Specifically, we project the internal activations of a pre-trained model into text using a retrieval approach and prompt the LLM to propose potential bias hypotheses. To detect biases from preprocessing pipelines, we convert the preprocessing data into text and prompt the LLM. Finally, ladder generates pseudo-labels for each identified bias, thereby mitigating all biases without requiring expensive attribute annotations.Rigorous evaluations on 3 natural and 3 medical imaging datasets, 200+ classifiers, and 4 LLMs with varied architectures and pretraining strategies {--} demonstrate that ladder consistently outperforms current methods. Code is available: \url{https://github.com/batmanlab/Ladder}."
}
